---
sidebarDepth: 2
---
# 第一期学习活动
## 第1天
### 任务:Web服务器基本工作原理学习
学习资料:
1、https://www.cnblogs.com/BOHB-yunying/articles/10911192.html
2、《Web工作原理》见附件
作业:写一篇小短文,发布在星球,小短文中需要回答几个问题
一个web服务器,最基本的由哪几个核心组件组成?
讲述一下,web服务器从收到一个请求,到完成这个请求的响应,主要流程是什么?
将自己理解的Web服务器工作原理,绘制一张图
附件:[Web工作原理.pdf](/web-server/files/day1-Web工作原理.pdf)
### 作业
看了一下网上搜索出来的感觉大都很专业,我就说说我自己的看法叭
web服务器组件我理解的是包含以下部分
- 配置文件、默认错误页面(像404, 500等错误页模板)
- 日志记录模块
- 端口监听模块
- 业务处理模块
- 请求响应模块
- 扩展模块(如反向代理等)
web服务器主要完成以下几件事
1. 监听到客户端发来的请求
涉及到计算机网络结构方面的知识
2. 处理请求
1. 取得请求方法(GET, POST, PUT等),解析url,进行路由
2. 通过路由知道客户端的请求
分成静态、动态两类,静态资源直接返回给客户端就行了,动态资源需要去对应提供服务的业务取得(像php, java, asp.net等等)
3. 将响应返回给用户
响应头中还包含一些扩展信息(像web服务器版本信息,MIME,缓存配置信息,静态资源还会有修改时间)

## 第2天
### 任务:HTTP协议学习 & F12 & wireshark抓包
学习资料:
https://www.ruanyifeng.com/blog/2016/08/http.html
https://zhuanlan.zhihu.com/p/77376952
https://haokan.baidu.com/v?pd=wisenatural&vid=9883591515530208938
作业:写一篇小短文,发布在星球,完成下面这些内容
- HTTP请求主要由哪几个部分组成?
- HTTP响应主要由哪几部分组成?
- HTTP头部和数据如何组织在一起?
- 这是世界上第一个网页:
http://info.cern.ch/hypertext/WWW/TheProject.html
使用浏览器访问这个URL,并使用wireshark抓包,分析请求和响应。
请求:Method、URI、HTTP版本、Headers
响应:状态码、Headers、HTML内容
### 作业
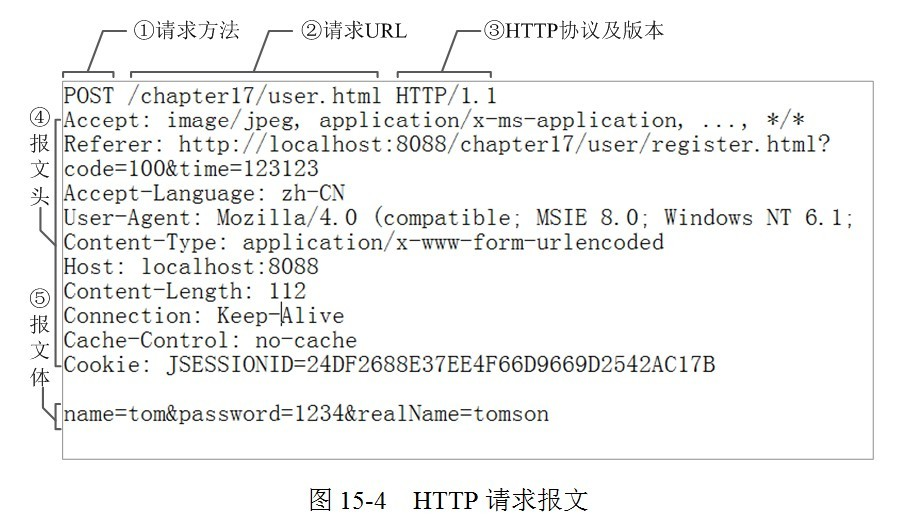
#### HTTP请求主要由哪几个部分组成?
**请求报文**
1. **请求行**:请求方法字段、URL字段和HTTP协议版本
例如:GET /index.html HTTP/1.1
get方法将数据拼接在url后面,传递参数受限
请求方法:GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT
2. **请求头**(key value形式)
- User-Agent:产生请求的浏览器类型。
- Accept:客户端可识别的内容类型列表。
- Host:主机地址
3. **请求数据**
post方法中,会把数据以key value形式发送请求
4. **空行**
发送回车符和换行符,通知服务器以下不再有请求头
#### HTTP响应主要由哪几部分组成?
**响应报文**
1. **状态行**
2. **消息报头**
**3. 响应正文**
#### HTTP头部和数据如何组织在一起?
#### Wireshark抓包
首先打开Wireshark,访问:http://info.cern.ch/hypertext/WWW/TheProject.html
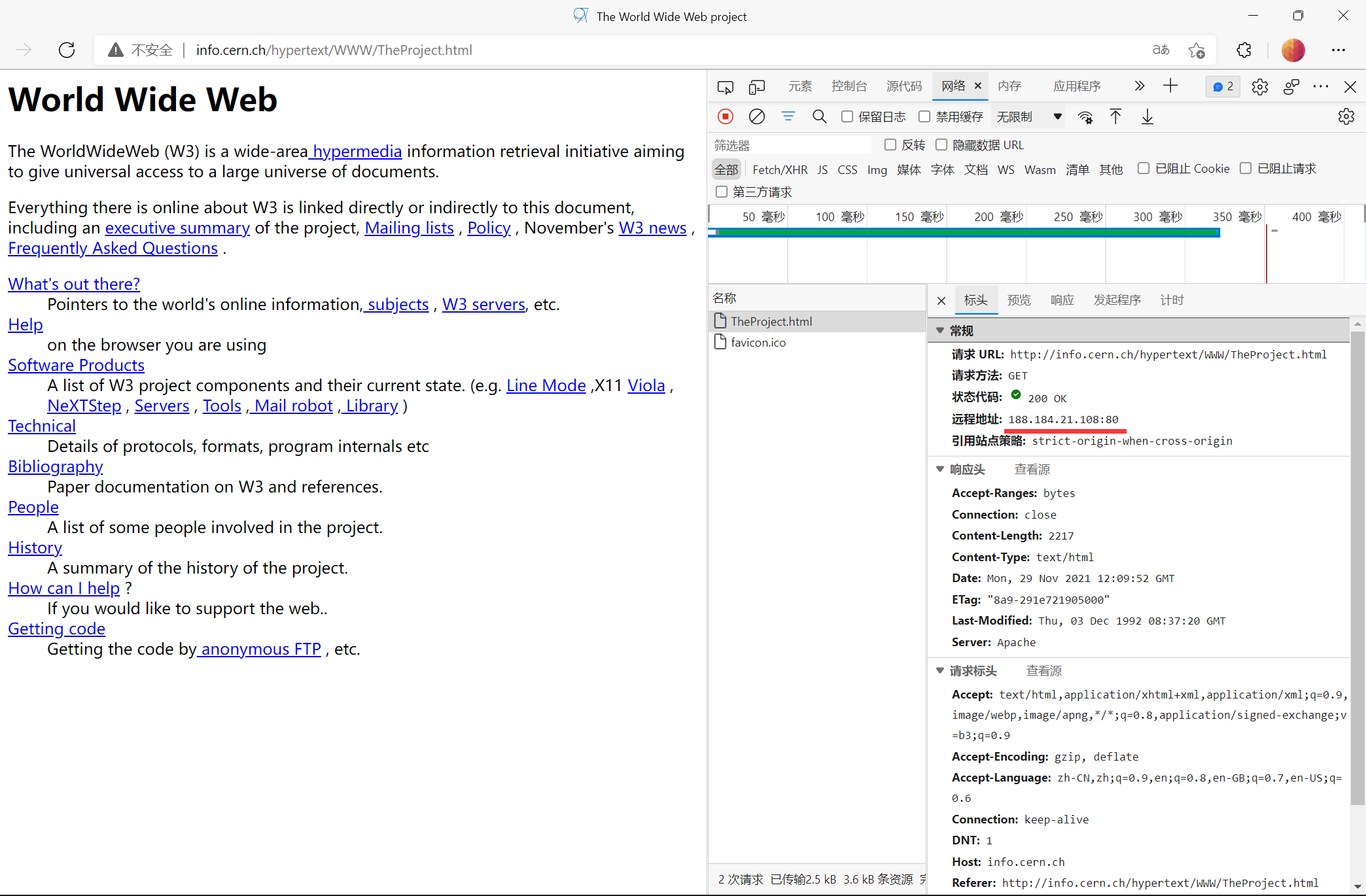
使用Wireshark抓包(按照 `ip.src == 188.184.21.108` 过滤,先 `Ctrl+R` 清除记录一次)
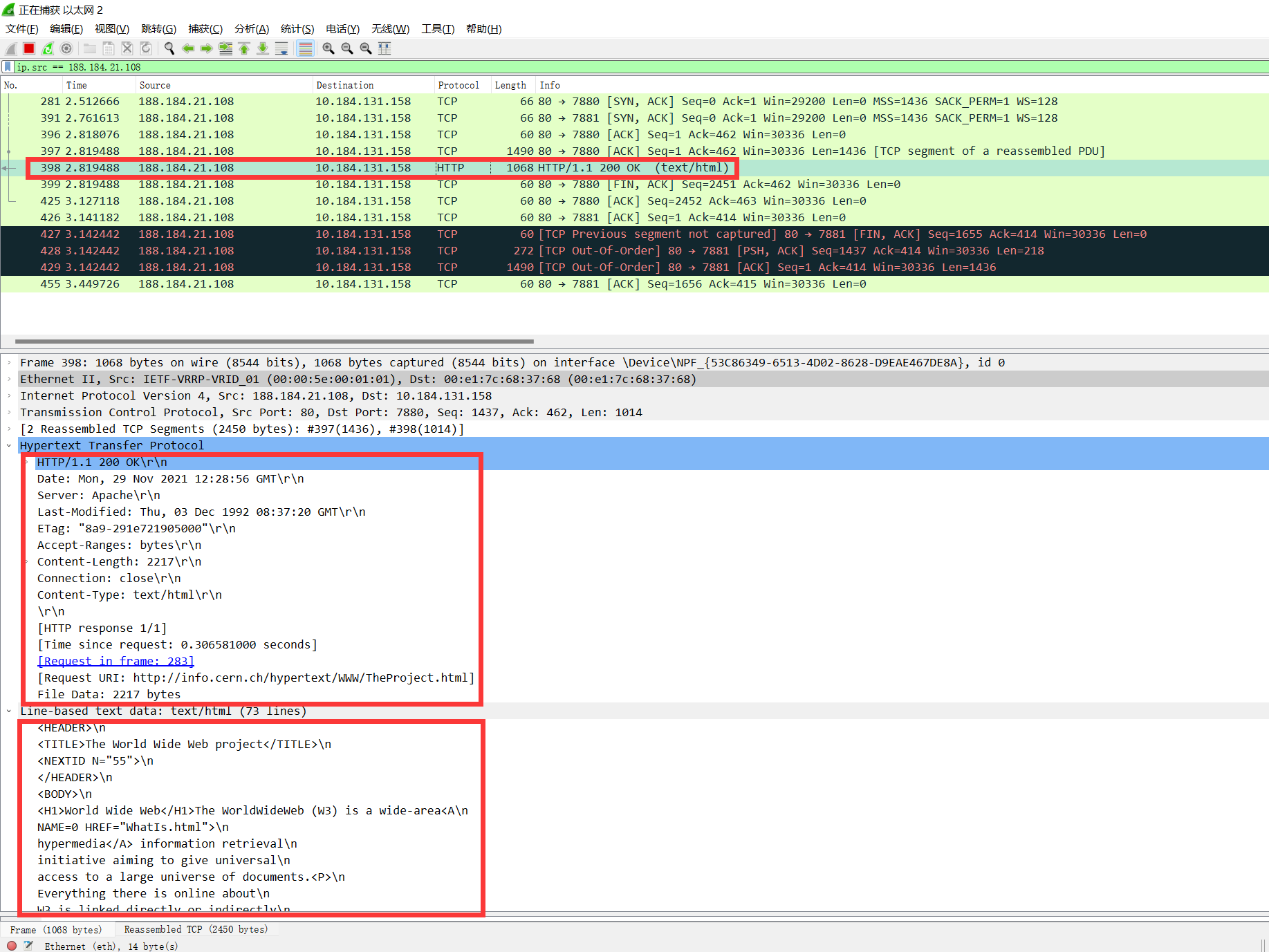
按 `Ctrl+Alt+Shift+T` 追踪TCP流(右键 追踪流、TCP流)
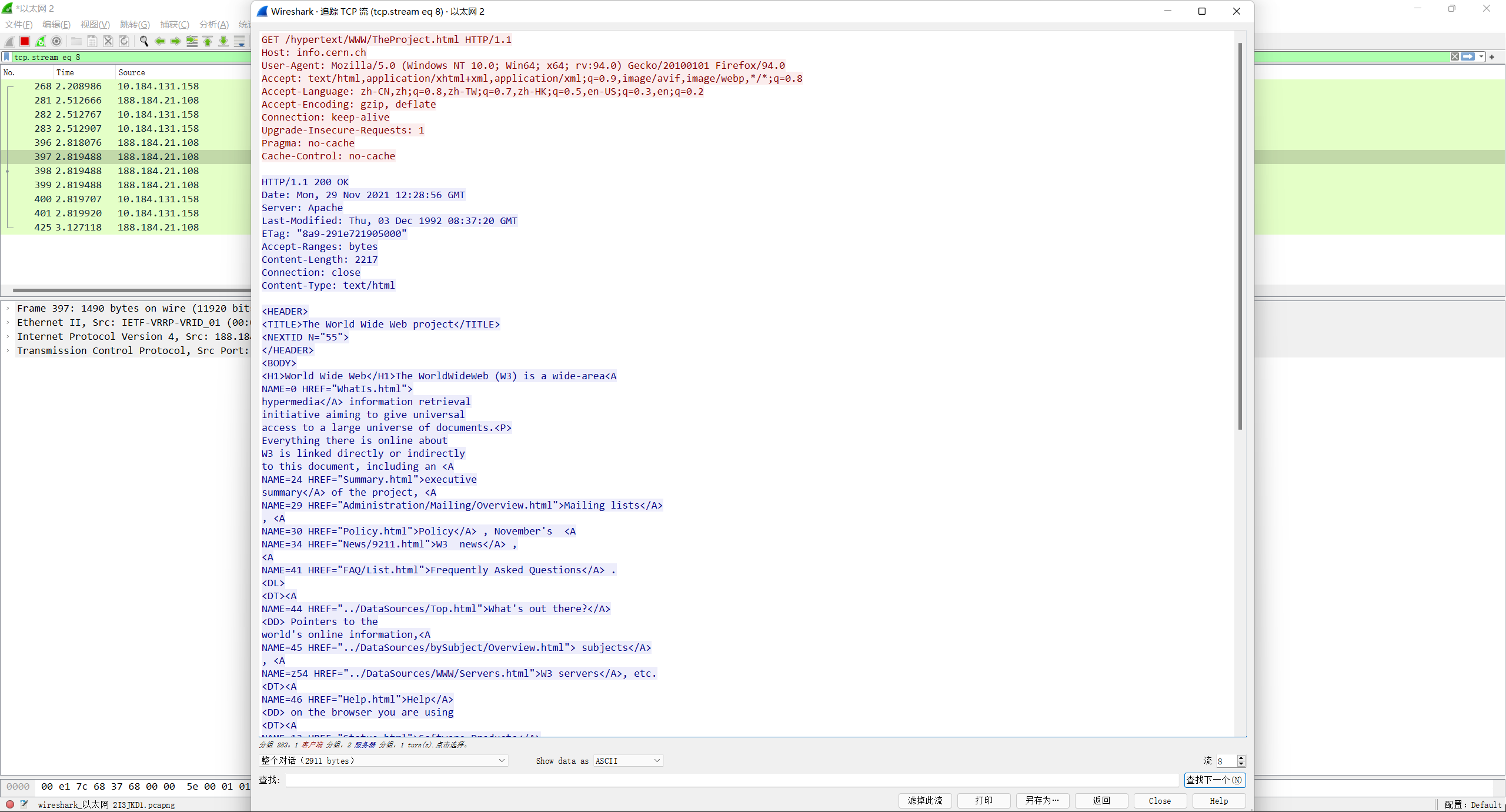
```
GET /hypertext/WWW/TheProject.html HTTP/1.1
Host: info.cern.ch
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Pragma: no-cache
Cache-Control: no-cache
HTTP/1.1 200 OK
Date: Mon, 29 Nov 2021 12:28:56 GMT
Server: Apache
Last-Modified: Thu, 03 Dec 1992 08:37:20 GMT
ETag: "8a9-291e721905000"
Accept-Ranges: bytes
Content-Length: 2217
Connection: close
Content-Type: text/html
The World Wide Web project
World Wide Web
The WorldWideWeb (W3) is a wide-area
hypermedia information retrieval
initiative aiming to give universal
access to a large universe of documents.
Everything there is online about
W3 is linked directly or indirectly
to this document, including an executive
summary of the project, Mailing lists
, Policy , November's W3 news ,
Frequently Asked Questions .
- What's out there?
- Pointers to the
world's online information, subjects
, W3 servers, etc.
- Help
- on the browser you are using
- Software Products
- A list of W3 project
components and their current state.
(e.g. Line Mode ,X11 Viola , NeXTStep
, Servers , Tools , Mail robot ,
Library )
- Technical
- Details of protocols, formats,
program internals etc
- Bibliography
- Paper documentation
on W3 and references.
- People
- A list of some people involved
in the project.
- History
- A summary of the history
of the project.
- How can I help ?
- If you would like
to support the web..
- Getting code
- Getting the code by
anonymous FTP , etc.
```
**请求**:
Method:GET
URI:/hypertext/WWW/TheProject.html
HTTP版本:HTTP/1.1
Headers:
Host: info.cern.ch
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Pragma: no-cache
Cache-Control: no-cache
**响应**:
状态码:HTTP/1.1 200 OK
Headers:
Date: Mon, 29 Nov 2021 12:28:56 GMT
Server: Apache
Last-Modified: Thu, 03 Dec 1992 08:37:20 GMT
ETag: "8a9-291e721905000"
Accept-Ranges: bytes
Content-Length: 2217
Connection: close
Content-Type: text/html
HTML内容:
略
## 第3天
### 任务:套接字编程基础知识
学习资料:
《网络编程》第六章(见附件)
https://www.jianshu.com/p/6ca1c102fc00
https://wenku.baidu.com/view/8d0f749881c758f5f71f6749.html
作业:写一篇小短文,发布在星球,回答几个问题
- 什么是套接字?
- 套接字有哪几个类型?
- 用套接字编写一个客户端和服务端,分别有哪几个步骤?
附件:[Linux网络编程.pdf](/web-server/files/day3-Linux网络编程.pdf)
### 作业
#### 什么是套接字?
套接字(socket)为通信的端点,每个套接字由一个 IP 地址和一个端口号组成。通过网络通信的每对进程需要使用一对套接字,即每个进程各有一个。
#### 套接字有哪几个类型?
套接字的类型
常用的TCP/IP协议的3种套接字类型如下所示。
流套接字(SOCK_STREAM):
流套接字用于提供面向连接、可靠的数据传输服务。该服务将保证数据能够实现无差错、无重复发送,并按顺序接收。流套接字之所以能够实现可靠的数据服务,原因在于其使用了传输控制协议,即TCP(The Transmission Control Protocol)协议。
数据包套接字(SOCK_DGRAM):
数据包套接字提供了一种无连接的服务。该服务并不能保证数据传输的可靠性,数据有可能在传输过程中丢失或出现数据重复,且无法保证顺序地接收到数据。数据包套接字使用UDP(User Datagram Protocol)协议进行数据的传输。由于数据包套接字不能保证数据传输的可靠性,对于有可能出现的数据丢失情况,需要在程序中做相应的处理。
原始套接字(SOCK_RAW):
原始套接字(SOCKET_RAW)允许对较低层次的协议直接访问,比如IP、 ICMP协议,它常用于检验新的协议实现,或者访问现有服务中配置的新设备,因为RAW SOCKET可以自如地控制Windows下的多种协议,能够对网络底层的传输机制进行控制,所以可以应用原始套接字来操纵网络层和传输层应用。比如,我们可以通过RAW SOCKET来接收发向本机的ICMP、IGMP协议包,或者接收TCP/IP栈不能够处理的IP包,也可以用来发送一些自定包头或自定协议的IP包。网络监听技术很大程度上依赖于SOCKET_RAW
原始套接字与标准套接字(标准套接字指的是前面介绍的流套接字和数据包套接字)的区别在于:原始套接字可以读写内核没有处理的IP数据包,而流套接字只能读取TCP协议的数据,数据报套接字只能读取UDP协议的数据。因此,如果要访问其他协议发送数据必须使用原始套接字。
#### 用套接字编写一个客户端和服务端,分别有哪几个步骤?
**服务端**:
1. 返回socket句柄
2. 设置套接字
3. 绑定端口,开始监听
4. 等待客户端连接
**客户端**:
1. 创建连接
2. 发送请求
-----
下面是网上找到的:
**服务器**:
1. socketfd = socket(........); 返回一个socket文件句柄
2. 设置套接字 setsockopt(socketfd , SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on)) < 0) // int on =1; SO_REUSEADDR表示可以重复使用一个端口
3. memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = ; (端口号) */
addr.sin_addr.s_addr = htonl(INADDR_ANY); /* 可以监听本地的所有的ip */
4. bind(socketfd , (struct sockaddr*)&addr, sizeof(addr)) != 0 ) // 绑定端口和IP
5. listen(socketfd , 10) != 0 /* 启动监测数据,最多可以同时连接10个客服端 */
6. clientfd = accept(socketfd , (struct sockaddr *)&client_addr, &addr_len); /* 等待客服端的链接,如果有链接,则建立链接 返回一个客服端的clientfd 会堵塞*/
**客户端**:
1. iSocketClient = socket(AF_INET, SOCK_DGRAM, 0); // SOCK_DGRAM 表示UDP
2. tSocketServerAddr.sin_family = AF_INET;
tSocketServerAddr.sin_port = htons(端口号); /* host to net, short */
//tSocketServerAddr.sin_addr.s_addr = INADDR_ANY;
3. iRet = connect(iSocketClient, (const struct sockaddr *)&tSocketServerAddr, sizeof(struct sockaddr)); // 连接
参考:https://blog.csdn.net/lgz929974811/article/details/106006925
## ★ 第4天
### 任务:编写一个TCP Client,发出一个简单的HTTP请求
学习资料:
- C/C++ socket编程:《网络编程》(见附件)
- Python socket编程:[https://www.cnblogs.com/george92/p/9291394.html](https://www.cnblogs.com/george92/p/9291394.html)
- Java socket编程:[https://m.runoob.com/java/java-networking.html](https://m.runoob.com/java/java-networking.html)
作业:
编写一个TCP Client程序,向http://www.baidu.com发起一个GET请求,并把服务器返回的数据打印出来
附件:[Linux网络编程.pdf](/web-server/files/day3-Linux网络编程.pdf)
### 作业
面向连接的socket的工作流程👇
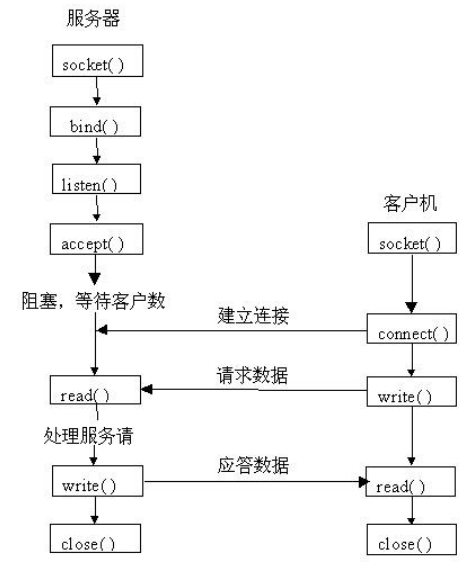
无连接的socket工作流程👇

## ★ 第5天
### 任务:编写一个TCP Server,发出一个简单的HTTP响应
学习资料:同昨天相同
作业:
编写一个TCP Server程序,当收到客户发来GET请求时(先不用管请求的具体是什么),都返回一个网页,网页的内容如下:
```html
这是我的第一个网页!
```
使用浏览器去访问自己写的这个TCP Server,截图展示访问效果
然后使用前一天自己编写的TCP Client去请求这个Server,通过Client将这个网页内容打印出来!
### 作业
## ★ 第8天
### 任务:改造TCP Server,发送一个HTML文件
学习资料:同任务4
作业:今天的任务只有一个改动,就是将第五天任务中的TCP Server返回的那个网页内容,改为从文件中加载,而不是固定写死在代码中。
## ★ 第9天
### 任务:使用多线程
学习资料:同任务4
作业:
在原来TCP Server基础上进行改造:当服务器收到连接请求时,启动一个单独的线程进行处理。并且不要关闭连接,继续监听这个客户端后续的请求。
附件:[Linux网络编程.pdf](/web-server/files/day3-Linux网络编程.pdf)
### 作业
## 第10天
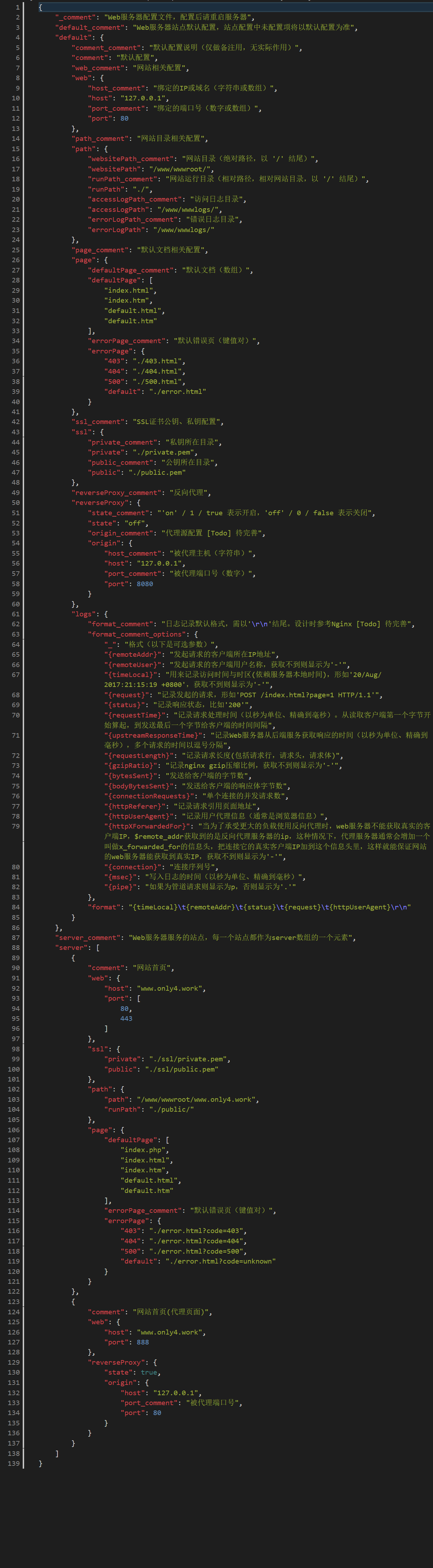
### 任务:设计并使用配置文件
学习资料:无
作业:
Web服务器一般会拥有多个参数,将服务器绑定的IP、端口、HTML文件所在的目录,写在配置文件中,程序启动的时候进行加载。
需要自己设计自己的Web服务器的文件格式,可以参考JSON、XML、YML等格式
### 作业
### 作业
### 作业
### 作业
### 作业
-----
11.29 11:01
其他人的作业
# 笔记
#### 回答轩辕大佬的问题:
##### 1.Web服务器 约等于 HTTP服务器 + 其他服务
(先不去管它这些操作具体的名称,单纯记录他的操作,后面再补)
包含:拿到数据包之后解包的东西、解析客户端的意图的东西、进行分类处理,或是提供某种文件、或是处理数据的东西、将结果装入缓冲区的东西、将以HTTP协议格式打包的东西、将该数据包推入Internet的东西
##### 2.主要流程是:接收数据 ⇒ HTTP解析 ⇒ 逻辑处理 ⇒ HTTP封包 ⇒ 发送数据
##### 3.用电脑画图画的,有点丑哈哈哈
#### 其他
顺便熟悉一下Markdown语法哈哈哈
稍微浏览了一下计网的书,感觉轩辕大佬的模式很好,通过项目学习,补充细节
在公众号搜到几篇文章,感觉挺有意思的,特别是有画小人的那个图解的
##### 网址信息收集
__*下面四个是一个系列的*__
[# 自己动手开发一个 Web 服务器(一)](https://mp.weixin.qq.com/s/cTfLlJNpKhixk31zlvaFgg)
[# 自己动手开发一个 Web 服务器(二)](https://mp.weixin.qq.com/s/2ulVC3L3w3YLcN4QS6lEvA)
[# 自己动手开发一个 Web 服务器(三)《https://wx.zsxq.com/mweb/views/weread/search.html?keyword=A》](https://mp.weixin.qq.com/s/Yn_4XhwNSAuqNFGAilSmAA)
[# 自己动手开发一个 Web 服务器(三)《https://wx.zsxq.com/mweb/views/weread/search.html?keyword=B》](https://mp.weixin.qq.com/s/B0CRXwKs8Z8FrW5tbEVHpg)
***
[#Web服务器工作原理详解(基础篇)](https://mp.weixin.qq.com/s/eb7xOT0-2uE9caaEfAqSCg)(就是轩辕大佬发的)
[# Linux下Web服务器详解](https://mp.weixin.qq.com/s/RZFQLpgjHj1V89BWyT8pQA)
[# Linux | 搭建Web服务器](https://mp.weixin.qq.com/s/X6u3SBhZ7A54-uczToD9Kw)
[# 来写一个属于自己的Web服务器](https://mp.weixin.qq.com/s/W5eDKKcHwlHtc-ssWOWBAg)
[# 开发一个属于自己的 web 服务器](https://mp.weixin.qq.com/s/zX8JGTQ-GwC2q63UuIQKFw)
[# 如何开发一个web静态服务器](https://mp.weixin.qq.com/s/H_t4jPSiBdogYVscoqUVaA)
[# 开发一个 web 服务器](https://mp.weixin.qq.com/s/EoDV6g93TzKMGDV-R12jqA)
[# web服务器开发之理论篇](https://mp.weixin.qq.com/s/ufQ68pdC7ZR3aI2gKZdsgw)
[# 手写一个 web 服务器!](https://mp.weixin.qq.com/s/cKgoSqIk97M1M9Q-gBOLBw)
[# Python 高手之路:从零开始打造一个Web服务器](https://mp.weixin.qq.com/s/3OWFXRTfhL30twQF4UzFUQ)
https://t.zsxq.com/YNZNRnm